Turing Unveils Japan’s First Autonomous Driving Vision-Language-Action Model Dataset”CoVLA Dataset” Paper Accepted at WACV 2025Turing also Releases a Japanese LLM for Autonomous Driving Multimodal Models, Achieving Best-in-Class Performance

Turing Inc. (Headquarters: Shinagawa, Tokyo; CEO: Issei Yamamoto; hereinafter “Turing”), a company dedicated to the development of fully autonomous vehicles, is proud to announce the development of the “CoVLA Dataset,” Japan’s first Vision-Language-Action (VLA) model dataset for autonomous driving. A portion of this dataset has been made publicly available, and the research paper “CoVLA: Comprehensive Vision-Language-Action Dataset for Autonomous Driving” (hereinafter “the paper”) has been accepted for presentation at the IEEE/CVF Winter Conference on Applications of Computer Vision 2025 (WACV 2025). This achievement is part of the company’s efforts under the Ministry of Economy, Trade and Industry (METI) and NEDO’s GENIAC AI development program.
Turing has also unveiled “vlm-recipes,” a Japanese LLM “Llama-3-heron-brain-70B, 8B” and a high-speed multimodal distributed learning library, alongside large-scale vision-language datasets “Wikipedia-Vision-JA” and “Cauldron-JA.”
(※) According to internal research as of September 2024, Turing’s CoVLA Dataset is the first VLA model dataset designed for autonomous driving in Japan.
Background
Fully autonomous driving requires systems capable of making high-level judgments using multiple types of data in complex and unexpected situations. Multimodal Large Language Models (MLLMs) have emerged as key technology to achieving fully autonomous driving, but progress has been hindered by the scarcity of annotated large-scale datasets for AI learning, and little research is available on how to apply such models to End-to-End (E2E) autonomous driving systems for route planning.
Overview of the CoVLA Dataset
The CoVLA (Comprehensive Vision-Language-Action) Dataset was developed by Turing to address these challenges. It is Japan’s first dataset designed for autonomous driving VLA models and consists of over 80 hours of driving data. The scale and variety of its annotations surpasses existing international datasets. Through scalable automated processes for data handling and caption generation, Turing has developed the VLA model “CoVLA-Agent” to describe driving environments captured by images in natural language and generate appropriate route plans.
CoVLA-Dataset:https://huggingface.co/datasets/turing-motors/CoVLA-Dataset-Mini
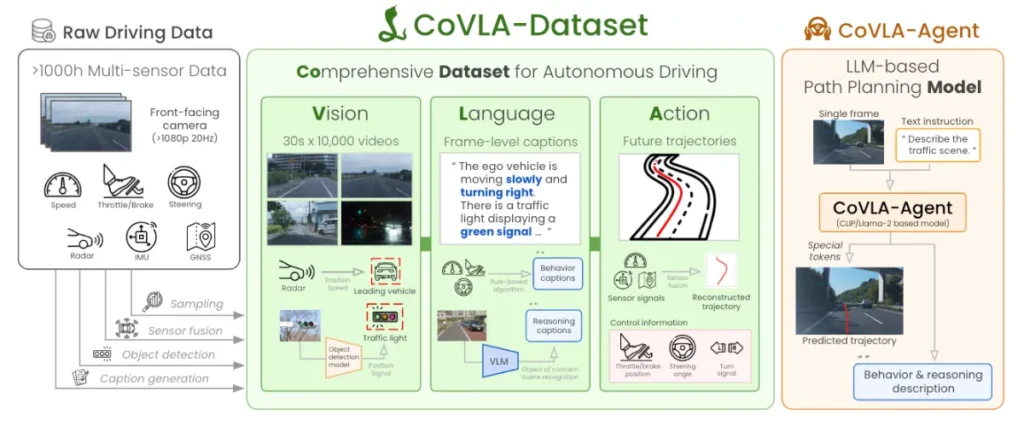
Future Outlook
MLLM verification with the CoVLA Dataset across various driving scenarios has demonstrated the model’s superior consistency in language generation and action output. These results confirm that VLA models leveraging vision, language, and action data are an effective approach for autonomous driving. In the future, we will release the full CoVLA Dataset to academic institutions to contribute to safer and more reliable autonomous driving systems.
The full research paper is available on arXiv: https://arxiv.org/abs/2408.10845
About the Japanese LLM “Llama-3-heron-brain-70B, 8B”
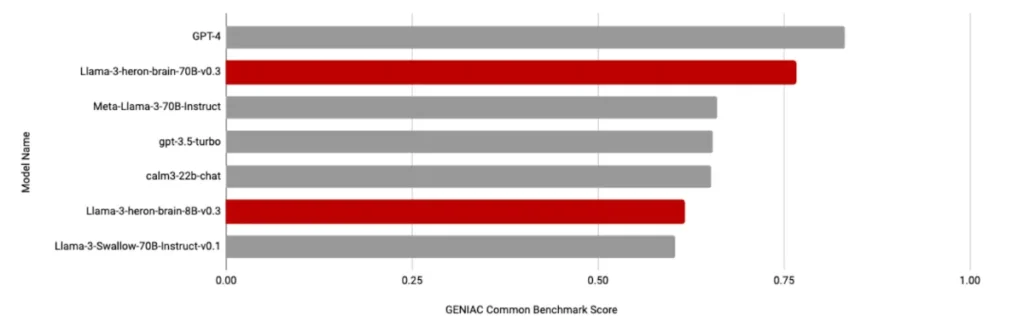
”The Llama-3-heron-brain-70B, 8B” Japanese-language LLM is trained to understand and respond to nuances in road conditions and the Japanese language. It is based on a multimodal vision-language model for autonomous driving, incorporating additional instructional tuning following pre-training in Japanese on Llama-3. In the shared GENIAC benchmark for language performance, the model outperformed GPT-3.5-turbo and achieved the second-highest score among participants, demonstrating strong capabilities in both Japanese and English. We are also using this LLM to develop a vision-language model with up to 73 billion parameters.
LIama-3-heron-brain-70B,8B:https://huggingface.co/turing-motors/Llama-3-heron-brain-70B-v0.3
Llama-3-heron-brain-8B-v0.3:https://huggingface.co/turing-motors/Llama-3-heron-brain-8B-v0.3
About the Vision-Language Datasets “Wikipedia-Vision-JA” and “Cauldron-JA”
To integrate visual information into Japanese LLMs, it is essential to train on large-scale pairs of images and text. Turing has developed new datasets closely aligned with Japanese language and culture. “Wikipedia-Vision-JA” consists of approximately 6 million entries derived from Japanese Wikipedia, containing image descriptions and related text. “Cauldron-JA” is a restructured version of Hugging Face’s “The Cauldron” in Japanese, encompassing 44 datasets related to visual-language tasks.
Wikipedia-Vision-JA:https://huggingface.co/datasets/turing-motors/Wikipedia-Vision-JA
Cauldron-JA:https://huggingface.co/datasets/turing-motors/Cauldron-JA
About the Multimodal Distributed Learning Library “vlm-recipes”
“vlm-recipes” is a distributed learning library developed by Turing under the GENIAC project to train large-scale vision-language multimodal models. It is designed to simplify and optimize multimodal model training by using PyTorch’s FullyShardedDataParallel (FSDP) as a backend, supporting distributed training across large GPU clusters. The open-source library offers an intuitive interface and flexible configuration options, making it easy to manage training for any VLM architecture or dataset.
Lead Developer: Kazuki Fujii
vlm-recipes:https://github.com/turingmotors/vlm-recipes
The results presented in this press release were achieved under the GENIAC project, a NEDO-funded initiative to strengthen Japan’s generative AI development capabilities.
Reference Press Release: https://tur.ing/posts/DK4fM1yr
About Turing
Turing is a startup dedicated to developing fully autonomous driving technology. We are creating an End-to-End (E2E) autonomous driving system capable of making all necessary driving decisions (steering, acceleration, braking, etc.) using only data from cameras. Through the development of multimodal generative AI models like “Heron” and generative world models like “Terra,” which understand complex real-world interactions, we will innovate in the autonomous driving domain and develop fully autonomous vehicles without steering wheels by 2030.
Company Overview
Company Name: Turing Inc.
Location: Gate City Osaki East Tower 4F, 1-11-2 Osaki, Shinagawa, Tokyo
CEO: Issei Yamamoto
Established: August 2021
Business: Development of fully autonomous driving technology
URL: https://tur.ing
Career Information
Turing is recruiting individuals who are passionate about transforming the world through Japan’s first fully autonomous driving technology. We regularly hold company introduction events and autonomous driving experience sessions. Feel free to reach out!
Careers Page: https://tur.ing/jobs
Media Contact
PR Team Contact (Hikaru Abe): pr@turing-motors.com